What Is Web Scraping And How Does It Work – 2024 Guide
Today, thanks to the Internet, almost all information is available to us at our fingertips. However, sometimes we also encounter obstacles and difficulties. Let’s say you’ve tried everything but failed to find the data you’re interested in. You have found the data on the Internet, but it cannot be downloaded or copied. Don’t worry, there may be a way to get them out. For example, web scraping. What is a web scraping and how it works, read in our guide for 2024.
What Is Web Scraping?
The websites we open every day are colorful, interesting, and full of useful or less useful information. Yet, have you ever thought about them in a broader context? To create websites, developers use text languages such as HTML and XHTML, which contain a real treasure trove of useful data. However, as most websites are made for people who are their users – machines cannot use this information in the right way. That is why today we use tools that can parse the content of pages and then convert them into a more convenient form.
How Does Web Scraping Work?
We can say that web scraping is a technique or a special API tool – and with its help, we can load a large amount of data from the websites we search for. The collected data is stored in a database or one of the local files on the computer. This information can only be displayed via a web browser. Unfortunately, web browsers do not offer us the ability to save copies for later use. Therefore, the only option is to copy and paste such data.
This way, web scraping allows us to have an automatic realization of the process of copying and saving data in a very short time. It is in some ways very similar to what we call indexing – but the difference still exists. First of all, web browsers work according to the rules set in the robot.txt file, while web scrapers do not have to.
Why Is Scraping Important In Digital Marketing?
A successful SEO expert knows and applies technical knowledge from several IT areas that help him to collect, process, and analyze data. It works more productively, faster, and achieves better results. It is not necessary to be an absolute expert in each of the areas but to look for the basics with which it is easier to kill the competition. Scraping is the extraction of data from web pages into local databases or tables. Let’s be clear from the start – this is about “white hat” data extraction.
According to webautomation.io – the basic way is to capture public data from HTML, RSS feeds, etc. When you master this skill – the logical continuation is to use the API offered by many web services. How does scraping benefit people working in Internet marketing? Certainly in a lot of ways. However, the most important thing is that they get a large amount of data for free: Meta tags, keywords, topics for writing blog articles, the number of likes on a page, the number of Twitter followers, the prices of your competitor’s products, email addresses, etc.
How Is It Done?
Here is a simple example:
Let’s say we find our competitor’s sitemap.xml file. We import it into Google Sheets – and then for each URL, we extract the meta title in the other column. If the site has 50 pages, we get all meta title tags in less than a minute. If the site has 1000 pages – then maybe about 5 minutes.
Imagine manually copying 1000 meta tags, how long would it take for such a job? For faster processing, the number of URLs is limited to 15. There are a lot of scraping methods. The above example is the application of the ImportXML function developed by Google. However, there are also plugins for WordPress that easily extract RSS feed, there is a great Chrome extension for scrape from the Inspect element – and there are the already existing SEO Tools for Excel. Whatever you do, try to stay working within the “white hat” principle.
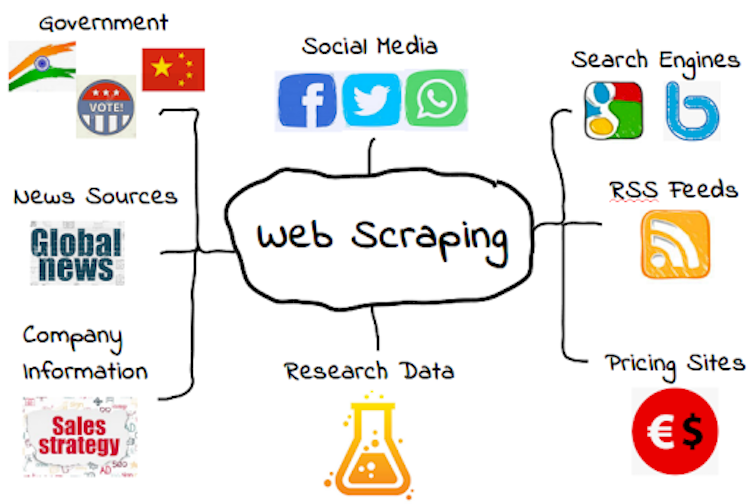
What Is Scraping Used For?
Web scraping is also called Web harvesting, or Web data extraction. We now know that it is the process of extracting a large amount of unstructured information from one or more websites, most often in HTML format, and transforming them into a form suitable for storage in a central database and analysis. The purpose of using web scraping is multiple, and we give you some of the reasons why and where it is most often done.

● Companies or state institutions
When implementing an IT project, whether it is a simple register of business partners, a media web portal, or a complex business information system – a very important segment that is often overlooked is filling the database with content. Web scraping programs perform such tasks for a fraction of the time it takes to enter data when people do so. The possibility of error is minimized by eliminating the human factor, and it brings incredible savings in human resources, time, and money to the client.
● Private clients
A common example is free forums. It often happens that the online community exceeds their limitations, but the owners are not able to move their forum to another platform or hosting because they are not allowed to access the database. The situation is similar to picture hosting accounts, Facebook accounts, etc. In such a situation, some of the web scraping technologies can help by picking up content in a short period, for example, forum – and automatically prepare it for switching to another platform.
Conclusion
We hope that now you have a little clearer concept of web scraping – as well as its role in business and digital marketing. If you are wondering which web scraper is best to use – we will answer that it depends mostly on your needs. Determine your data collection needs as clearly and precisely as possible – and you will have a clearer idea of which web scraper software is best for you.